


追踪法在行业污染分类中的应用
导读:用追踪法进行模糊聚类分析主要可以分为:数据标准化、标定(建立模糊矩阵)、模糊聚类三个部分。其余的23个行业污染程度居中。模糊聚类,追踪法在行业污染分类中的应用。
关键词:模糊聚类,追踪法,行业污染
1 引言
传统的聚类分析是一种硬划分,每个对象都只能归于一类,而现实的分类问题往往伴随着模糊性,即每个对象属于某一类是程度问题。这时候单纯的严密的理论推导和数学计算往往达不到很好的效果,相反,模糊逻辑在这方面具有极大的优势【1】,随着模糊数学的不断发展,聚类的算法也在不断的更新和发展.新产生的聚类算法更加适用于生产生活,并且和计算机技术的结合也更加紧密,追踪法就是这样的一种算法。和传统的聚类方法相比较,追踪法在建立模糊矩阵后,不需要计算等价闭包,也不需要画图或者编程求解模糊矩阵的最大生成树和编网,只需要对模糊矩阵进行算法复杂度为O(n2)的数据分析,就可以得出聚类结果。
2 模糊聚类新算法---追踪法的计算步骤
用追踪法进行模糊聚类分析主要可以分为:数据标准化、标定(建立模糊矩阵)、模糊聚类三个部分。
2.1 数据标准化
这里所说的数据标准化,就是根据模糊数学相关理论,去掉数据中的量纲,并将数据压缩到区间[0,1]上。
设论域
为被分类的对象,每个对象可以使用m个指标表示其性状:
于是得到原始数据为:
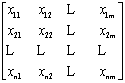
在实际问题中,不同的数据由于其量纲不同,无法进行比较。为了使有不同量纲的量也能进行比较,通常需要对数据作适当的变换。一般采用平移标准差变化法来解决这个问题,计算公式如下:
=
经过变换后,变量的均值为0,标准差为1,且消除了量纲的影响。
2.2 标定(建立模糊矩阵)
设论域
依照传统聚类方法确定相似系数,建立模糊相似矩阵,
与
的相似程度
,确定
的方法主要借用传统聚类的数量积法、夹角余旋法、相关系数法、指数相似系数法、绝对值倒数法、绝对值指数法、闵可夫斯基距离法、马氏距离法和兰氏距离法等方法。具体采用哪些方法进行聚类分析,主要依据实际情况决定。
2.3 使用追踪法进行模糊聚类
在建立了模糊相似矩阵后,就可以用追踪法进行数据分析。主要步骤如下:
1 模糊相似矩阵R出发,求得其
截矩阵
; 2 于对称性,先得到截矩阵
下三角部分(不包括主对角线元素),再记录该部分的非零元素下标,并存在二元数组A[t][2]中;
3 令g=1,且将g存入数组b[n]中;
4 行搜索数组A[t][2],若数组a中有元素A[i][j](1≤i≤n,1≤j≤2)与g相等,且同一行的另一元素(A[i][j±1])在数组b中不存在,则将A[i][j±1]存入数组b[n]中;
5 令g遍取数组b中元素,重复步骤4,直到没有新的元素加入数组b;
6 将数组b中元素按行存入二元数组C[n][n]中;
7 令g取1~n中任一个数组C[n][n]中不存在的元素,重复步骤4~6;直到数组C[n][n]中的元素总数等于待分类对象的个数n为止【2】。
3 追踪法在行业排污情况中的应用
下面,以从国家统计局网站找到2005年工业按行业分废气排放及处理情况的统计数据为例,说明模糊聚类新算法在行业排污聚类中的应用,数据如表1所示:
表1 行业排污数据统计表
| 行业 | 二氧化硫排放量(万吨) | 二氧化硫去除量(万吨) | 工业烟尘排放量(万吨) | 工业烟尘去除量(万吨) | 工业粉尘排放量(万吨) | 工业粉尘去除量(万吨) |
| 煤炭开采和洗选业 | 21 | 5.7 | 10.9 | 141.8 | 24.6 | 9.7 |
| 石油和天然气开采业 | 3.2 | 11.6 | 1.4 | 9.9 | 0.1 | 0.1 |
| 黑色金属矿采选业 | 4.3 | 1.9 | 1.7 | 19.2 | 3.9 | 31.7 |
| 有色金属矿采选业 | 6.7 | 6.3 | 2.7 | 22.4 | 2.8 | 31.0 |
| 非金属矿采选业 | 5.7 | 10.9 | 6.8 | 30.7 | 8.8 | 22.1 |
| 农副食品加工业 | 15.6 | 6.4 | 20.4 | 97.2 | 2.1 | 4.7 |
| 食品制造业 | 9.4 | 3.5 | 5.1 | 41.7 | 0.6 | 1.2 |
| 饮料制造业 | 10.7 | 3.1 | 9.0 | 38.1 | 0.2 | 0.6 |
| 烟草制品业 | 1.3 | 1.2 | 0.6 | 6.4 | 0.2 | 1.7 |
| 纺织业 | 29.6 | 8.7 | 12.8 | 120.4 | 0.3 | 1.0 |
| 纺织服装鞋帽制造业 | 1.5 | 0.6 | 0.7 | 6.3 | 1.3 | 5.1 |
| 木材加工及木竹滕棕草制品业 | 4.8 | 0.7 | 5.5 | 20.7 | 1.6 | 10.5 |
| 家具制造业 | 0.4 | 0.5 | 0.2 | 6.8 | 0.2 | 5.6 |
| 文教体育用品制造业 | 0.3 | 0.1 | 0.2 | 2.6 | 0.4 | 15.1 |
| 医药制造业 | 6.4 | 2.5 | 4.2 | 32.5 | 0.1 | 0.2 |
| 化学纤维制造业 | 11.5 | 5.8 | 4.6 | 117.8 | 0.1 | 1.8 |
| 金属制品业 | 2.6 | 0.6 | 1.7 | 6.3 | 1.0 | 3.1 |
| 通用设备制造业 | 5.5 | 1.4 | 3.8 | 33.1 | 2.3 | 10.3 |
| 专用设备制造业 | 3.3 | 2.3 | 21 | 10.5 | 1.7 | 4.7 |
| 交通运输设备制造业 | 4.1 | 1.5 | 3.0 | 39.6 | 3.2 | 14.1 |
| 电气机械及器材制造业 | 2.7 | 0.9 | 1.5 | 5.0 | 0.3 | 0.1 |
| 通信计算机及其他电子设备制造业 | 1.7 | 0.7 | 0.8 | 6.1 | 0.4 | 5.8 |
| 工艺品及其他制造业 | 0.5 | 0.1 | 0.5 | 0.9 | 0.2 | 0.5 |
| 燃气生产和供应业 | 1.9 | 0.8 | 1.4 | 25.5 | 0.1 | 2.2 |
从表一的数据中不难看出,各行业由于行业发展水平不同,所以各行业排污的情况也不相同,传统的硬性分类方法,很显然不适合对表一的数据进行分类。这里采用模糊聚类新方法——追踪法来处理以上数据。详细计算步骤如下:
3.1 数据标准化
根据表一中的数据,可得到数据的原始矩阵为:
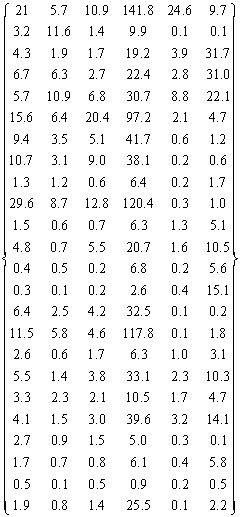
运用标准差法,可消除数据中的量纲, 其Matlab程序如下:
%计算平均值
for k=1:1:m
sum=0;
fori=1:1:n;
sum=sum+x(i,k);
end
mean(k)=sum/n;
end
%计算s(k)
for k=1:1:m
sum=0;
fori=1:1:n;
temp=(x(i,k)-mean(k))^2;
sum=sum+temp;
end
s(k)=sqrt(sum/n);
end
%消除量纲
fori=1:1:n
for k=1:1:m
x(i,k)=(x(i,k)-mean(k))/s(k);
end
end
3.2 建立模糊矩阵
本文应用闵可夫斯基距离法建立模糊相似矩阵,其计算方法如下:
式中,C和
是两个适当选择的参数。
取C=0. 1(保证
的取值在0与1之间) m=3 q=2
=1可得计算方法为:
其Matlab程序如下:
for i=1:1:n
for j=1:1:n
sum=0;
for k=1:1:m
temp=x(i,k)-x(j,k);
temp=temp*temp;
sum=sum+temp;
end
r(i,j)=1-0.1*sqrt(sum);
end
end
3.3 使用追踪法进行模糊聚类
本次聚类选取α=0.71,从模糊相似矩阵R出发,求得其
截矩阵
;先得到截矩阵
下三角部分(不包括主对角线元素),再记录该部分的非零元素下标,并存在二元数组A[t][2]中(本次分类中t=136),再按照本文2.3中描述的方法,对数据进行追踪分类。写作,模糊聚类。最后,可将行业污染数据分成三类:1 煤炭开采和洗选业;2农副食品加工业和纺织业;3 其余23个行业为一类。
通过分类发现:煤炭开采和洗选业属于重度污染行业,其对环境的影响,远远大于其他行业;农副食品加工业和纺织业属于污染较小的行业,相对而言对环境的影响较小;其余的23个行业污染程度居中。写作,模糊聚类。写作,模糊聚类。
4 结论
使用模糊聚类的新方法—追踪法,可以较为准确的对行业污染进行分析。写作,模糊聚类。写作,模糊聚类。和传统的聚类分析方法相比较,追踪法的运算复杂度只有O(n2),具有运算速度快,分类准确等特点。写作,模糊聚类。比较适合于处理大量数据分类的问题,具有一定的应用前景。
参考文献
[1]方宏斌.模糊聚类及其实际应用[J].广东通信技术,2005,05:9-13
[2]张兴华.模糊聚类分析的新算法[J].数学认知与实践,2005,35(3):138-141

使用微信“扫一扫”功能添加“谷腾环保网”




